Traduttore di codice morse in Haskell
Reading time: 4 minutesTable of contents
Qualche tempo fa ho trovato su /r/programming questo vecchio thread con un interessante esercizio di programmazione. La richiesta era in apparenza molto semplice:
Chi sa scrivere il più piccolo/pulito/intelligente traduttore di Codice Morse?
Per chi non lo sapesse il Codice Morse è un alfabeto composto di soli punti e linee, utilizzato per inviare messaggi a distanza tramite luce, suono o simili mantenendoli umanamente comprensibili.

¶ L'idea più semplice
La soluzione più semplice e intuitiva è ovviamente quella di associare a ogni sequenza di punti e linee la lettera dell'alfabeto corrispondente usando un dizionario o simili:
#pseudocodice:
".-" = 'a'
"-..." = 'b'
"-.-." = 'c'
#...eccetera
Hm. Funziona, ma non è né corto né "intelligente". Si può fare di meglio!
¶ Strutturare i dati
Come si possono esprimere questi dati in maniera più concisa? Beh, una lettera in morse è composta da un punto o una linea, che può essere o non essere seguito da un altro punto o linea e così via. Si può provare a dividere le lettere su questa base!
In base al primo simbolo:
punto linea
eishvufarlwpj tndbxkcymgzqo
In base al secondo:
punto linea
eishvufarlwpj tndbxkcymgzqo
punto linea punto linea
ishvuf arlwpj ndbxkcy mgzqo
A ogni passaggio la struttura si dirama... come in un albero! Infatti il codice morse può essere rappresentato da un albero come questo: 1
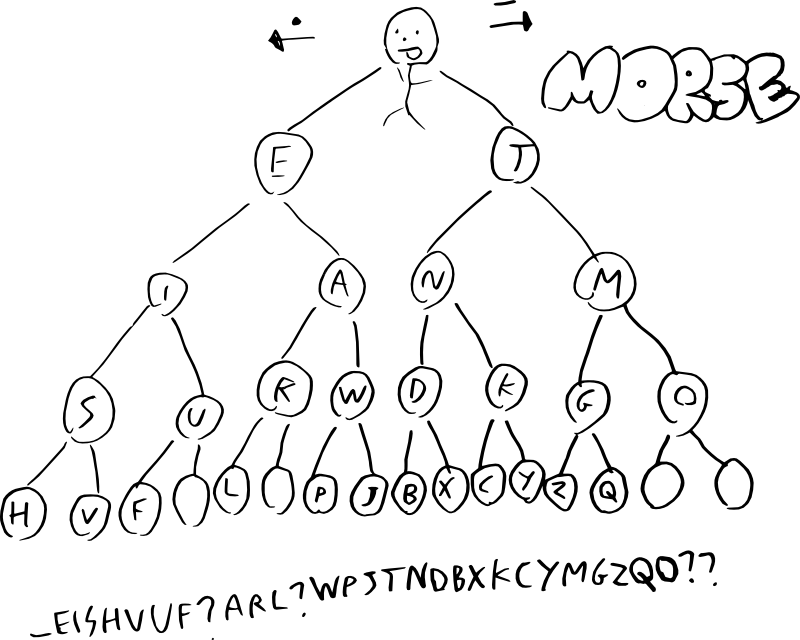
Per ogni simbolo componente la lettera si scende a sinistra nel caso di un punto o a destra nel caso di una linea, fino ad arrivare nella foglia che conterrà la traduzione.
Come esprimere tutto questo in un linguaggio di programmazione? Si può creare un tipo di dato (come è già stato fatto qui)...
...Oppure comprimere tutto l'albero in un'unica stringa! 2
Se per ogni foglia si scrive la lettera corrispondente seguita da due stringhe di lunghezza uguale contenenti i due rami collegati a quella foglia (rappresentati con lo stesso metodo) 3 si ottiene " eishvuf?arl?wpjtndbxkcymgzqo??". I punti di domanda sono dei segnaposto che indicano la mancanza di una lettera corrispondente a quella sequenza (le caselle dell'albero vuote).
¶ Il codice
Ho pensato di implementare la soluziona a questo problema in Haskell: un linguaggio funzionale puro in cui mi sto cimentando che probabilmente apparirà molto spesso in queste pagine... Non mi dilungo a descriverlo ulteriormente, dato che esistono già numerose risorse al riguardo4.
¶ Codice:
Il funzionamento è piuttosto semplice: viene applicato un fold alla lettera in morse, percorrendo man mano i punti e le linee. L'accumulatore è l'albero descritto prima e la funzione non fa altro che dividere in due la stringa e scegliere la prima o la seconda metà a seconda del simbolo (punto o linea). Terminato il fold, la foglia corrente (quindi la testa della stringa) sarà la lettera tradotta.
Escludendo gli import, l'esplicitazione dei tipi e la dichiarazione separata di half il codice è composto solo da 5 righe per la decodifica (che era l'obiettivo principale) e 8 per la codifica. È un ottimo risultato considerando che l'unico codice più corto è quello in python, che però non è altrettanto leggibile
Artwork by: mia sorella (R) (TM)
Lo so, può sembrare una complicazione in più, ma alla fine porta a un codice più corto e comunque leggibile (come richiesto nel thread)
Si può immaginare di ripiegare l'albero trascinando la cima in basso a sinistra
Magari potrei scrivere un articolo dedicato più avanti.